JRDB-Pose 2022
Advancing the state-of-the-art for human pose estimation and tracking in-the-wild.
Advancing the state-of-the-art for human pose estimation and tracking in-the-wild.
JRDB-Pose contains new manually-labeled annotations for body pose and head box across our entire train and test video set. These annotations include 600,000 human body pose annotations and 600,000 head bounding box annotations, making JRDB-Pose one of the largest publically-available dataset of ground truth human body pose annotations. Crucially, annotations come from in-the-wild videos and include heavily occluded poses, making JRDB-Pose both difficult and representative of the real-world environment.

JRDB-Pose uses a 17 keypoint set for pose annotations, where each keypoint is annotated with its position and visibility score.
1. head
2. right eye
3. left eye
4. right shoulder
5. neck
6. left shoulder
7. right elbow
8. left elbow
9. center hip
10. right hand
11. right hip
12. left hip
13. left hand
14. right knee
15. left knee
16. right foot
17. left foot
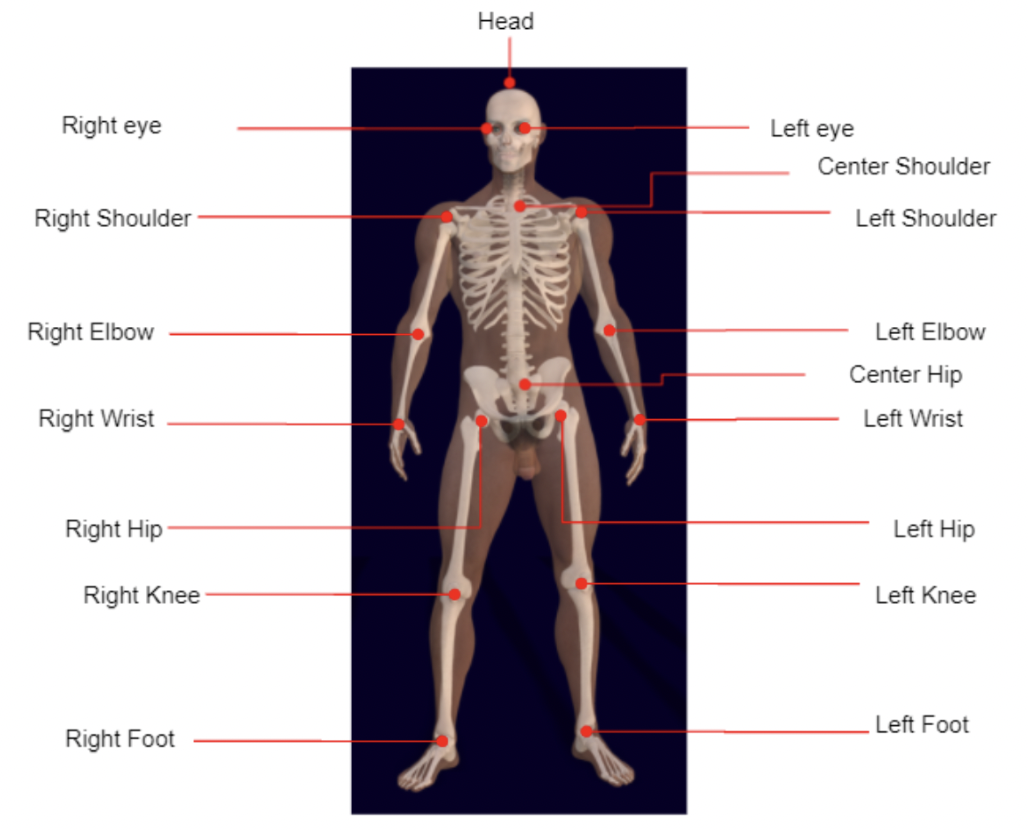
Annotated joint locations of JRDB-Pose
{0, 1, 2}:
| Visibility | Meaning | Description |
|---|---|---|
| 0 | Invisible | This joint is out of frame or especially difficult to annotate. |
| 1 | Occluded | The joint is somewhat occluded (by another body part of an object), but it is reasonably easy to infer its location. |
| 2 | Visible | The joint is fully visible and in view of the camera. |
For each scene, we provide a .json file with the COCO-style annotations dictionary for that
scene. The body pose data itself is contained in the annotations list, which looks like the
following. Annotations with body pose information use category_id=2.
"annotations": [
{
"id": 9403
"image_id": 822,
"track_id": 37,
"area": 5463.6864,
"num_keypoints": 17,
"keypoints": [229, 256, 2, ..., 223, 369, 0],
"bbox": [204.01, 235.08, 60.84, 177.36],
"category_id": 2,
}
]
These annotations were collected over a period of several months. Annotators were asked to label the locations of all 17 keypoints shown above. In case a keypoints is occluded, but its location is still reasonably possible to infer, its location is properly annotate, meaning that our dataset contains many severely occluded keypoints. We generally annotate all people in a scene whose bounding boxe area is at least 6500 pixels; below this, we find that the location of keypoints are too close together to be useful. While JRDB videos are 15fps, we annotate at 7.5fps (every other frame) and linearly interpolate the middle frames to provide further high-accuracy annotations with little additional work. These annotations, including interpolated frames, are provided as JRDB-Pose.
Every individual pose annotation comes with a track_id property, which remains consistent
for the person across the video sequence.
For each scene, we provide a .json file with the COCO-style annotations dictionary for that
scene. The data for head bounding boxes is contained in the annotations list use
category_id=1. Head bounding box annotations look like the following:
"annotations": [
{
"id": 9403
"image_id": 822,
"track_id": 37,
"area": 476.0476,
"bbox": [244.36, 239.79, 20.44, 23.29],
"category_id": 1,
}
]
Every head box annotation comes with a track_id property, which remains consistent for the
person across the video sequence.
We evaluate leaderboard results using both AP and OSPA-Pose. You can find the evaluation toolkit here:
Toolkit (on Github)

